
About Me
🚀 I am a passionate Junior Data Engineer with a strong foundation in data pipelines, ETL processes, and SQL. My experience spans projects involving data extraction, transformation, and loading into cloud-based databases like BigQuery. 💻 I have hands-on experience with Python, Apache Airflow, and Mage AI, and I’m eager to leverage my skills to tackle complex data challenges and drive impactful, data-driven decisions. 📊 I’m a lifelong learner, always excited to grow and innovate in the ever-evolving field of data engineering. 🌟
Skills

Data Engineering Tools: Apache Air
Databases: PostgreSQL, MySQL, MongoDB
Tools: Docker, Kubernetes, Terraform
Programming Languages: Python, SQL, Java
ETL/ELT: Data Pipeline Design, Data Warehousing, Real-Time
Data Warehousing: database solutions, schema design, data modeling, and normalization.
My Projects
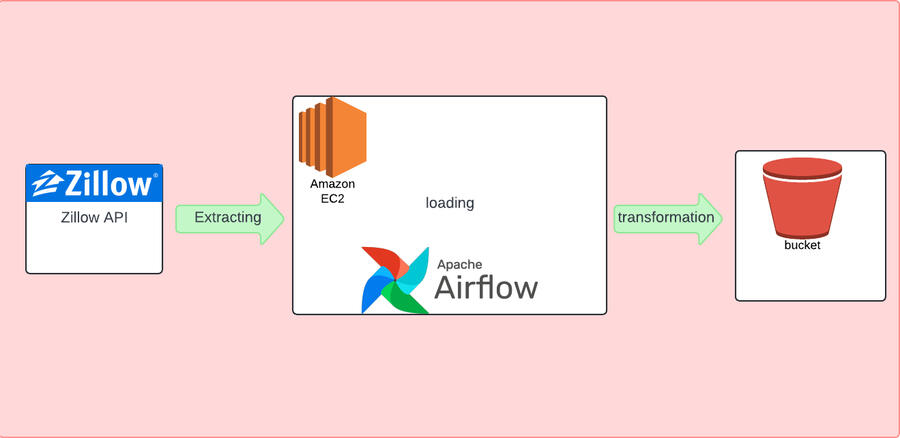
Zillow API Data Pipeline Using Airflow
This project is a data pipeline that extracts real estate data from the Zillow API, processes it, and then stores it in an AWS S3 bucket. The entire process is orchestrated using Apache Airflow.
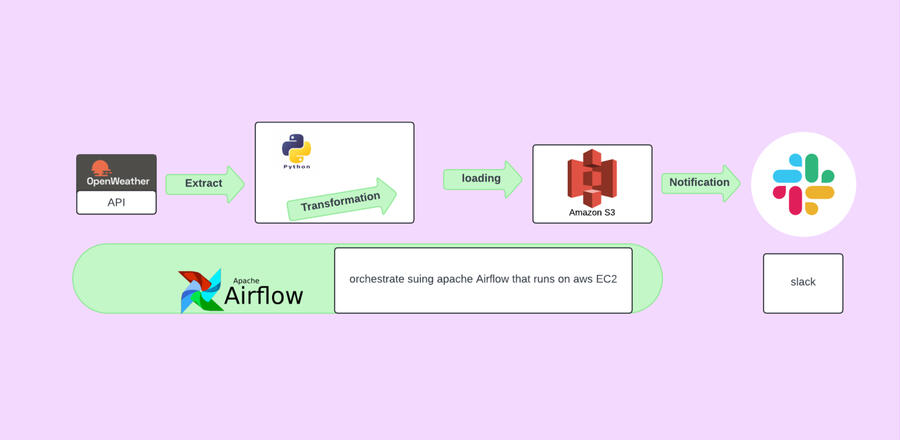
Weather Data ETL Pipeline With Apache Airflow
This project contains an Apache Airflow (DAG) for extracting, transforming, and loading weather data from the OpenWeatherMap API to an S3 bucket. The pipeline also sends notifications to a Slack channel upon completion.
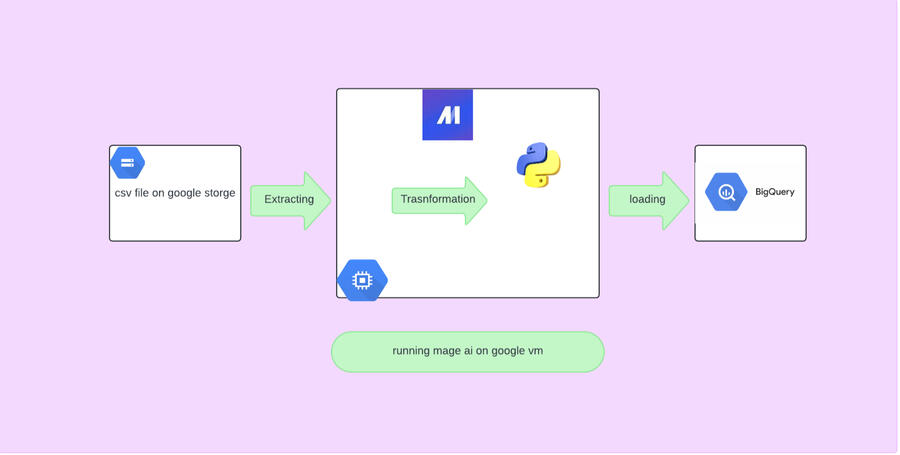
Car Rental Data Engineering Pipeline
This project is a data engineering pipeline that processes car rental customer data. The pipeline extracts flat CSV files generated using the Python faker library, transforms the data into dimensional tables, and loads it into Google BigQuery. The entire ETL (Extract, Transform, Load) process is orchestrated using Mage AI
E-Commerce-Retailers-pipeline
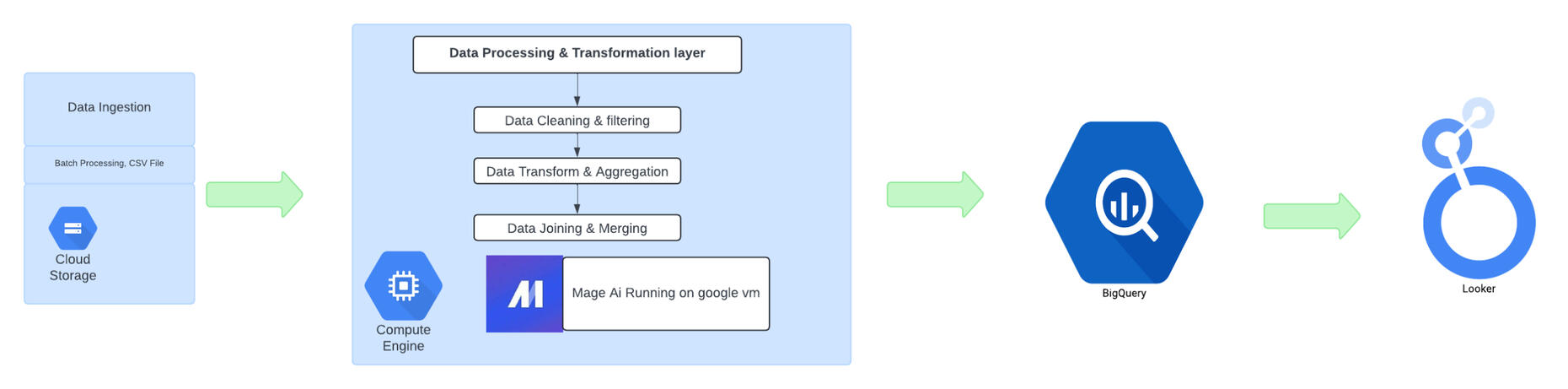
Project Overview
This project focuses on building a data engineering pipeline for E-Commerce Retailers. The pipeline automates the process of extracting CSV files from Google Cloud Storage, transforming the data, and loading it into Google BigQuery. Finally, the data is visualized using Looker Studio to create insightful dashboards. The pipeline is orchestrated using Mage AI, which is hosted on a Google Cloud VM.Architecture
The pipeline architecture is designed to efficiently handle large volumes of data and consists of the following key components:Data Ingestion: CSV files are extracted from Google Cloud Storage.
Data Transformation: Data transformations are performed using Mage AI, which runs on a Google Cloud VM.
Data Loading: The transformed data is loaded into Google BigQuery.
Data Visualization: The data in BigQuery is visualized using Looker Studio to create dashboards.
My Education
University of Missouri-Kansas City| Batcher's of Computer Science
Metropolitan Community College | Associate of Computer science
Thanks!
Thanks for taking the time to visit my portfolio! 🙌 If you'd like to chat about me joining your team, feel free to email me using the form below. 📧